
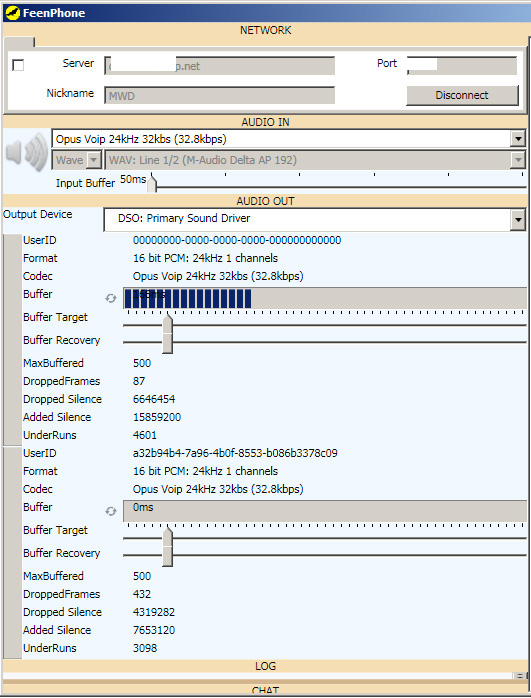
NOTE: THIS IS AN OLD POST, THE FeenPhone INTERFACE HAS CHANGED. THE Buffer Recovery IS NOW HIDDEN IN ADVANCED OPTIONS, AS YOU WILL PROBABLY NOT NEED TO ADJUST IT.
The Input Buffer slider determines how much audio data the microphone builds up before it sends it to the app, this ensures that the app gets a constant stream of data from the mic in the event that something else going on within the system causes the microphone not to be able to send data for a moment or two.
.
The WAVE input seems to require a longer buffer than the WASAPI driver, so the minimum for WAVE is 50ms; but the minimum for WASAPI is lower and can be queries from the device. The Audio-Technica AT2005USB documentation claims that the mic supports a minimum buffer length of 3ms. I found 3ms to be too short, so I set the default buffer length for the WASAPI devices to be three times the minimum reported by the device, 9ms for the AT2005.
.
The Output Buffer is how much data from the remote client is saved up before playing it. This is a jitter buffer and it prevents audio playback from pausing when packets arrive late. If any packets are delayed, the output buffer still has audio to play while waiting for them to come in. On slower or congested networks, a higher value will be needed.
The amount of output that is buffered is shown as the colored horizontal bar above the buffer target slider. The Buffer Target slider adjusts how much of that buffer the program should try to maintain. When I said that you may need more buffer for slower connections I meant that you may need to turn up the buffer target. The colored horizontal bar shows how much data is actually buffered.
.
The Buffer Recovery setting is the input to an algorithm that determines what to do when the jitter buffer is getting too large. Underflow occurs when the jitter buffer runs out of data and there’s nothing to play, this occurs when the packets are delayed. However the packets eventually come it, so you might have 1000ms of packets on the wire that FeenPhone is waiting for in an underflow state; when that 1000ms comes in, perhaps all at once, the jitter buffer jumps up to 1000ms The recovery functions attempts to play out that audio faster than it should be so that the buffer length can be reduced, it does this by looking through the data stream and finding microseconds of silence to remove. The higher the “Buffer Recovery” setting is, the more aggressively the algorithm tries to remove this silence from the stream.
.
The whole buffer recovery thing is very rough, and was really just a proof of concept. I think I there are better more accepted ways to “catch up” with the buffer. There are some examples of this in the WebRTC code which will have a less noticeable effect of quality than the way I’m doing it.
